Maya Kaczorowski
Esta semana, McKinsey publicó un informe titulado "Hacer una transición segura a la nube pública", el resultado de entrevistas con expertos en seguridad de TI en casi 100 empresas de todo el mundo.
Aprovechando la experiencia de los expertos en seguridad de Google
Cloud y McKinsey, la investigación presenta un marco estratégico para la
seguridad de TI en entornos híbridos y en la nube, y brinda
recomendaciones sobre cómo migrar a la nube sin perder de vista la
seguridad.
La investigación muestra lo que muchos ya saben: que la adopción de la
nube pública se está acelerando gracias a una mayor flexibilidad
técnica, escalas más simples y menores costos operativos.
Lo que es emocionante es que la investigación también revela que muchos Chief Information Security Officers (CISOs) ya no ven la seguridad como un inhibidor
de la adopción, sino una oportunidad: "En muchos casos, los CISOs
reconocen que los recursos de seguridad de los proveedores de servicios
en nube son pequeños, "Escriben los autores, y ahora estas compañías se
centran en cómo adoptar y configurar mejor los servicios en la nube para
una mayor seguridad.
Cuando se implementa correctamente, la adopción de la nube pública puede reducir significativamente el costo total de propiedad (TCO) para la seguridad de TI.
Esto requiere que las empresas, los proveedores de servicios en la nube
y los proveedores de servicios externos trabajen de forma conjunta y
transparente dentro de un modelo de seguridad compartido.
Google Cloud siempre ha creído en crear confianza a través de la
transparencia, publicando previamente una descripción detallada de la seguridad de nuestra infraestructura, explicando nuestro modelo de responsabilidad compartida
y cómo ya protegemos a nuestros usuarios y clientes en las capas
inferiores de la pila, y estamos encantados de ver el respaldo detallado
de McKinsey al mismo enfoque.
Enfoques de seguridad comunes, y sus intercambios.
Cada empresa tiene diferentes necesidades de TI, pero el informe
encontró dos decisiones comunes de seguridad que toman las empresas
cuando adoptan servicios en la nube: (1) definir el perímetro y (2)
decidir si volver a diseñar las aplicaciones para una mayor capacidad de
administración, rendimiento y seguridad en el nube (curiosamente, solo
el 27% de las empresas encuestadas lo hacen, el cambio es difícil).
La investigación identifica tres arquetipos comunes para la seguridad
del perímetro: backhauling, cleansheeting y adopción de controles del
proveedor de la nube de forma predeterminada.
- Backhauling
permite a las empresas continuar gestionando la seguridad de TI en las
instalaciones, con una puerta de enlace externa que conecta el centro de
datos con la nube pública.
Aproximadamente la mitad de las empresas encuestadas actualmente usan
este modelo, pero solo el 11% planea seguir haciéndolo, ya que puede
evitar que las empresas obtengan ciertos beneficios de la nube, como la
agilidad.
- Cleansheeting
requiere una mayor inversión y experiencia, ya que exige el rediseño de
la seguridad de TI en torno a un "perímetro virtual" y el
aprovechamiento de múltiples herramientas y servicios nativos de la
nube.
- Usar los controles del proveedor de la nube
es la solución más rentable, pero, dependiendo del proveedor de la
nube, puede limitar la autonomía y puede ofrecer capacidades limitadas.
McKinsey utiliza estos tres modelos, junto con la decisión de volver a
diseñar las aplicaciones para la nube, para identificar seis
"arquetipos" para la seguridad en la nube. Cada arquetipo tiene sus propias compensaciones:
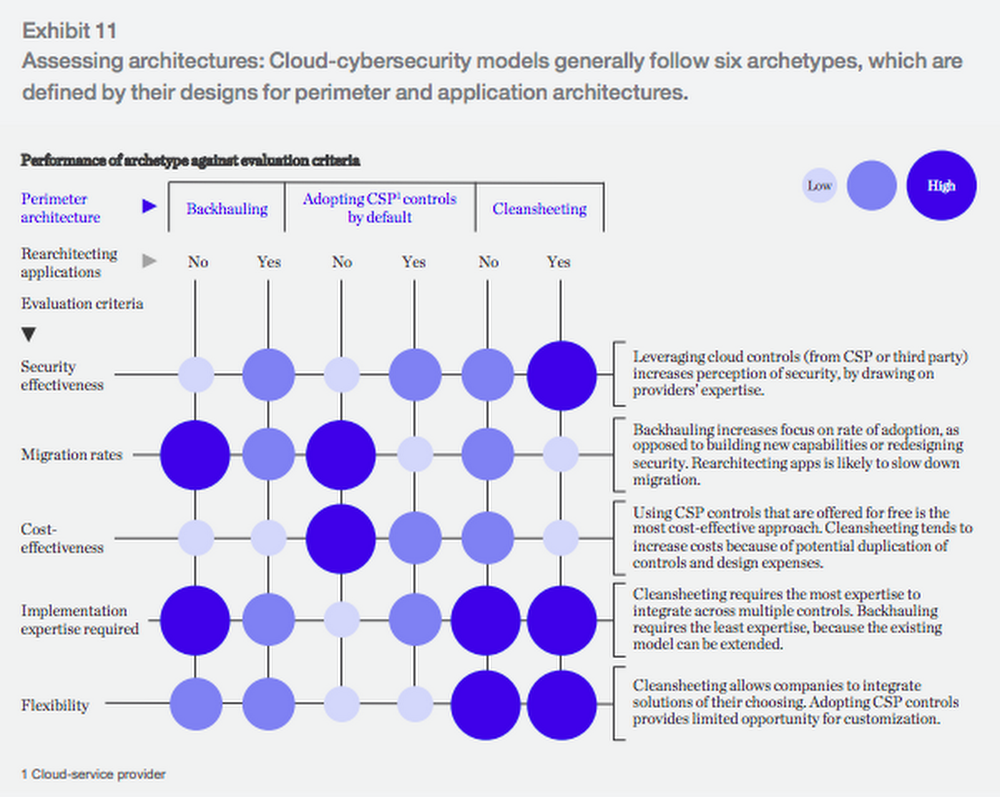
No
existe una "respuesta correcta" para la seguridad al realizar un cambio
a la nube, sino que depende de la experiencia, la flexibilidad y las
decisiones de costos de su empresa.
Y, no tienes que usar solo un arquetipo. Por ejemplo, Evernote describe en su historia de migración a Google Cloud Platform :
"Para la mayoría de nuestros controles encontramos una versión de plataforma en la nube equivalente. Para el cifrado de datos en reposo, obtuvimos un control de seguridad que no habíamos diseñado por nuestra cuenta. Para
algunos controles, como la lista blanca de IP, tuvimos que adaptar
nuestra arquitectura de seguridad para no depender de los controles de
red tradicionales ".
- Rich Tener, Director de Seguridad, Evernote
La economía de la seguridad en la nube.
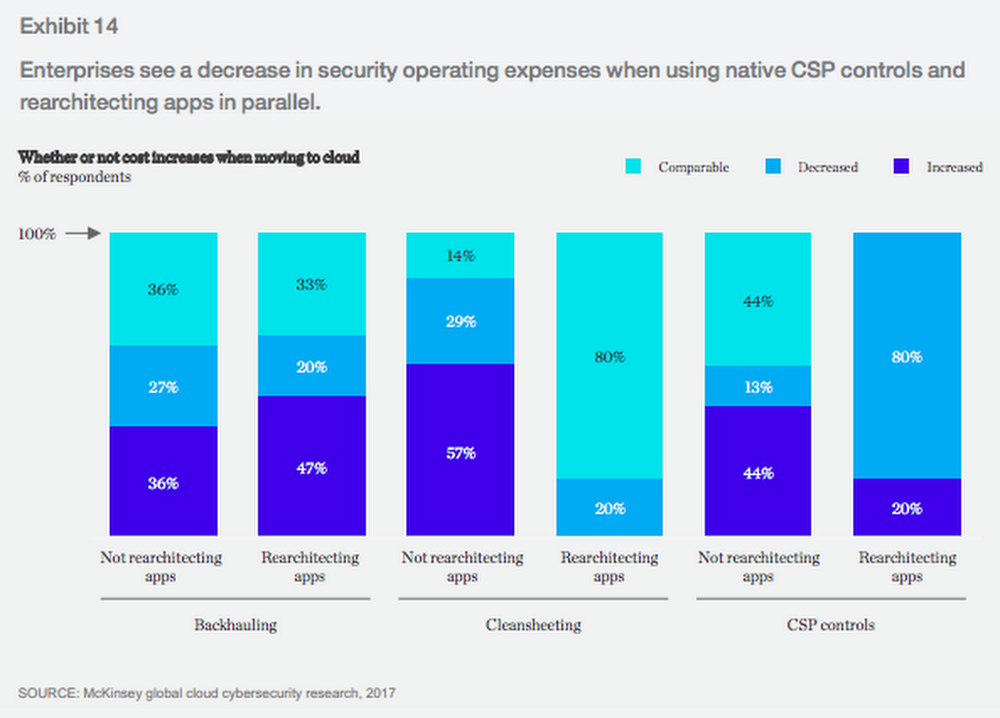
Confiar en los controles de seguridad del proveedor de servicios en la nube es "el enfoque más rentable", escriben los autores.
"A medida que las organizaciones mueven cada vez más aplicaciones a la
nube pública y se inclinan por usar controles CSP nativos, es probable
que disminuyan los costos operacionales y de seguridad". El ochenta por
ciento de las empresas que eligen basarse principalmente en los
controles y redesarquitectores del proveedor de la nube sus aplicaciones
en paralelo ven ahorro de costos.
Entonces, si está planeando una migración a la nube, ¿dónde debe enfocar sus esfuerzos de seguridad?
McKinsey preguntó a los encuestados sobre su enfoque para aplicar
controles de seguridad en la nube en varias áreas para descubrir qué
están haciendo las empresas:
- Gestión de identidad y acceso (IAM ): el 60% de las empresas utilizan soluciones de IAM en las instalaciones; en solo tres años, los encuestados esperan que ese número se reduzca a la mitad. En Google, proporcionamos una herramienta llamada Google Cloud Directory Sync, que ayuda a los usuarios a traer identidades existentes a Google Cloud y administrar permisos en la nube de forma nativa con IAM.
- Encriptación
: la mayoría de los encuestados encriptan datos tanto en reposo como en
tránsito, y aún más (más del 80% en ambas categorías) lo harán dentro
de tres años. Google Cloud ya encripta los datos en reposo de forma predeterminada y en tránsito cuando cruza un límite físico.
- Seguridad perimetral
: hoy, el 40% de las empresas están retrocediendo el tráfico de datos y
utilizando controles de seguridad de red locales existentes, pero eso
disminuirá, con solo 13% esperando usar el mismo enfoque en 3 años.
Para ayudar a las empresas a pasar al control perimetral basado en la
nube, Google Cloud permite a los usuarios conectarse a su entorno local
utilizando Interconexión Dedicada, un túnel VPN IPsec, interconexión directa o interconexión de operadores . Los usuarios de Google Cloud también pueden controlar su perímetro con una nube privada virtual (VPC).
- Seguridad de la aplicación
: el 65% de los encuestados define los estándares de configuración de
seguridad para las aplicaciones basadas en la nube, pero menos del 20%
usa herramientas o implementaciones basadas en plantillas. Para solucionar esto, Google Cloud ofrece Cloud Security Scanner, una forma automatizada de escanear aplicaciones para detectar vulnerabilidades comunes.
- Monitoreo operacional
: el 64% de los encuestados usa las herramientas SIEM existentes para
monitorear las aplicaciones en la nube en lugar de crear un nuevo
conjunto para la nube. Los usuarios de Google Cloud pueden exportar registros de Stackdriver al SIEM de su elección.
- Puntos finales del servidor
: el 51% de los encuestados tiene un alto nivel de confianza en el
enfoque de su proveedor de servicios en la nube para la seguridad del
punto final del lado del servidor. Los clientes de Google Cloud pueden usar una variedad de herramientas de los socios para la seguridad de los puntos finales.
- Puntos finales del usuario : el 70% de los encuestados cree que la adopción de la nube pública requerirá cambios en los puntos finales del usuario. Google creó el modelo de seguridad empresarial BeyondCorp para permitir que sus empleados trabajen desde cualquier lugar, y nuestros clientes pueden hacer lo mismo con Identity Aware Proxy . Además, los Chromebook proporcionan actualizaciones automáticas de software y ejecutan aplicaciones en un entorno limitado restringido.
- Gobernabilidad regulatoria
: cuando se adopta la nube pública, las empresas deben navegar por los
requisitos de gobernabilidad y cumplimiento, con la ubicación de los
datos y las regulaciones financieras que encabezan la lista de
preocupaciones de los encuestados. Google Cloud tiene un amplio espectro de cumplimiento , que incluye PCI, SOX e HIPAA.
El informe también incluye un plan táctico de 10 pasos para una migración en la nube exitosa. Para obtener más información, descargue el informe completo.